My Longest AI Session Was 13 Hours. I Came Out With Two Things Worth Knowing.
5.68 billion tokens, several shipped products, and two things to consider that came from spending all that time working with AI.
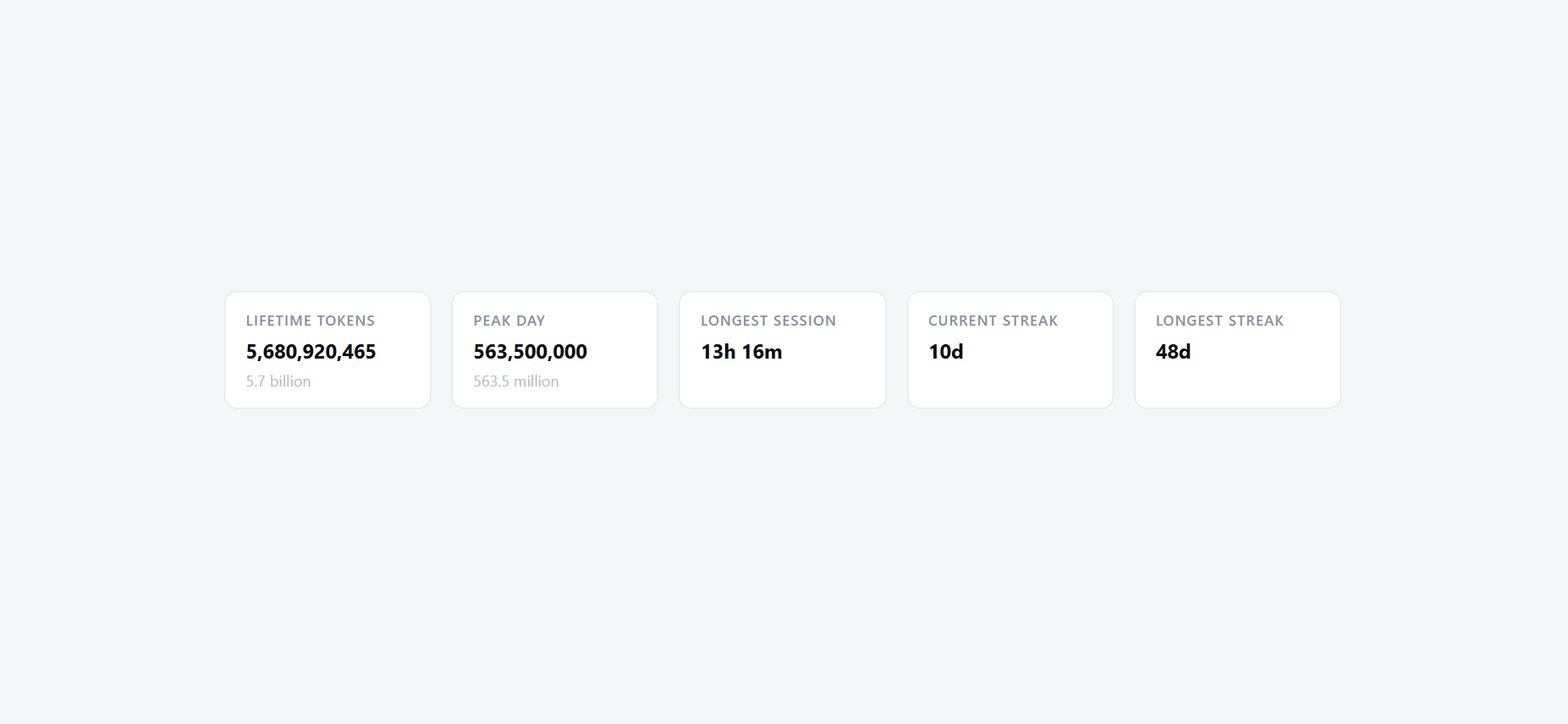
My tracked AI usage across ChatGPT, Claude, Claude Code, and Codex sits at 5.68 billion tokens. My longest session ran 13 hours and 16 minutes. I have done several more like it. Once had to take a break after 48 days straight of working with AI and broke that streak. I have shipped several products along the way. I am not a programmer.
That is a conservative count. It excludes my product API traffic, ElevenLabs usage, my full ChatGPT chat history, and a business account where another amount of significant amount of work happened.
The median developer spends about two hours a day on AI-assisted work. Understandable also as adoption is still underway. [1] I have been at it longer than most people’s workdays, on most days. Although I have plenty of observations, two things immediately stand out.
There is no single best model
I run Claude Opus 4.6, 4.7, 4.8, GPT-5.5 Pro on Codex, and Gemini 2.5 Flash among other frontier versions on the API side. I did not set out to run that many. I ended up here because each one is genuinely better at a different job, and using the wrong one quietly costs you.
4.6 still feels best conversationally and it outputs what you expect with your input better than anything else I have used. Anthropic has shipped two successors and I will still switch back to 4.6 for back-and-forth chat iterations or for Claude Design where the model needs to really understand what I actually mean. It is better at that than 4.7 was. It is better at that than 4.8 is.
4.7 is and was the AI vision workhorse. 4.8 is the best coding model I have worked with, and it is not close. It’s, I hate to use this word, magical. [2] 4.8 also made effort levels matter. Effort controls existed before, but this is the first version where they feel sharp enough to route on. It’s the first model I can confidently switch back and forth from High all the way to Max and back down again. I rarely use it on Max. Extra seems to be the 4.8 sweetspot. The question becomes which model, and at what intensity. Too much effort on a simple task wastes time and money. Too little on a hard one and you redo the work. You learn that calibration by burning through it.
On the API side the problem compounds. One of my products runs on Gemini 2.5 Flash and Flash-Lite, and those models are being retired. [3] Right now I am choosing between Google’s next Flash generation and DeepSeek V4-Pro, which recently made a permanent price cut. [4] New model, new vendor, and a whole different set of tradeoffs. That decision comes back every few months. It is never as simple as the benchmarks imply.
I won’t even get to the love affair Anthropic’s Claude Status service degradation alerts had with my phone. I unsubscribed. I just take it for granted: one or several of the Claude models will be failing today. It’s not a knock on Anthropic. OpenAI keeps it to themselves better.
Cost does not creep. It jumps.
The second thing the long hours taught me: when AI cost moves, it moves fast.
You run a few tasks, the bill is nothing. You let an agent work through a longer context, and the bill steps up hard, because in agentic work the model re-reads its accumulated context on every turn and that context grows fast.
When you read that one company’s AI compute costs hit half a billion dollars in a single month, [5] the scale is obviously different. The pattern is not. Cost tracks compute appetite, not output.
I learned the small version on my own meter. Cheaper place to learn it.
So now I assess the economics before I wire anything up. I cache aggressively. I keep prompts short and everything it includes has a specific reason and context. The frontier models and the high-effort settings get saved for jobs where the extra reasoning changes the answer. Everything else runs cheap. That discipline was not obvious to me at the start. It is now. It is also the piece most teams with big budgets skip until the bill arrives.
What the hours bought
I formed these opinions from the inside, by sitting in the tools long enough to watch them fail in specific, repeatable ways, and to learn what to do when they do.
5.68 billion tokens. Thirteen-hour sessions. Several shipped products. You cannot govern what you have not operated, and you cannot integrate what you have not lived in.
References
[1] DORA AI-assisted work time data, via “AI Coding Adoption 2026: 50 Statistics From 7 Surveys,” Digital Applied, May 2026. https://www.digitalapplied.com/blog/ai-coding-adoption-statistics-2026-50-data-points
[2] Anthropic, “Introducing Claude Opus 4.8,” May 28, 2026. https://www.anthropic.com/news/claude-opus-4-8
[3] Google, Gemini API model deprecations. https://ai.google.dev/gemini-api/docs/deprecations
[4] Reuters, “China’s DeepSeek to make permanent 75% price cut on flagship V4-Pro AI model,” May 23, 2026. https://www.reuters.com/world/china/chinas-deepseek-make-permanent-75-price-cut-flagship-v4pro-2026-05-23/
[5] Axios / Fast Company, Anthropic AI compute costs report, May 2026. https://www.fastcompany.com/91550884/claude-ai-costs-climb-company-spent-half-a-billion-dollars-in-a-single-month-report